
Lately, we were approached by a government-owned financial institution in Papua New Guinea to device a secure data solution for their branch office at Wewak, which was constantly offline due to intermittent network failures over the existing service provider. This, in turn, impacted their business and hampered productivity. Our recommendation was to use a secondary service provider with secure tunnelling as a backup with an automatic failover option. Whereby, when the primary link fails the backup link takes over the role of data transport – “automatically” and seamlessly.This is a fantastic solution for customers who are looking for agility, resiliency, redundancy and 100% uptime for their links between the head-office and branch officers (given there is no power failure :)). Unfortunately, you cannot buy the automatic failover solution wrapped up in a box off-the-shelf. It is something you would need to carefully design, make hardware improvements and use proven traffic engineering techniques to accomplish.What we have learnt over the years working with Data Networks in the Pacific Islands is as much as you want to blame the service provider(s) for the poor network performances in throughput and link instability; it is just as easy to find creative solutions. Sometimes there are situations beyond the control of the service providers. For instance, there could be a cable/fibre cut on a long-haul link or an exchange been vandalised or it could also be the RF signal has lost its line-of-sight due to harsh weather conditions. Then, there are other instances where services providers oversubscribed their links and there is constant contention on the network. This is just bad practice.In this article, we like to explore handful options on how to best use the technologies you currently have at your disposal to improve network stability and performance and not succumb to the limitations, not within your control.
Automatic Failover As An Option
By far the most effective data network solution available for all Pacific Islands right now, period. So what is this? Simply put, Automatic failover is having two service providers instead of one integrated into your network to transport data with one acting as primary and the other as secondary. Should the primary provider fail the secondary kicks in automatically and seamlessly without any intervention from your IT team?You could take this solution one step further and engineer those service provider links to behave in active/active mode or in more complex variations you could even load-share between the two service providers. The best part is provisioning/conditioning these service provider links; they are completely transparent to the service provider thus, you achieve complete control of your traffic flow.The diagram below illustrates one variation of this technology used in Papua New Guinea.
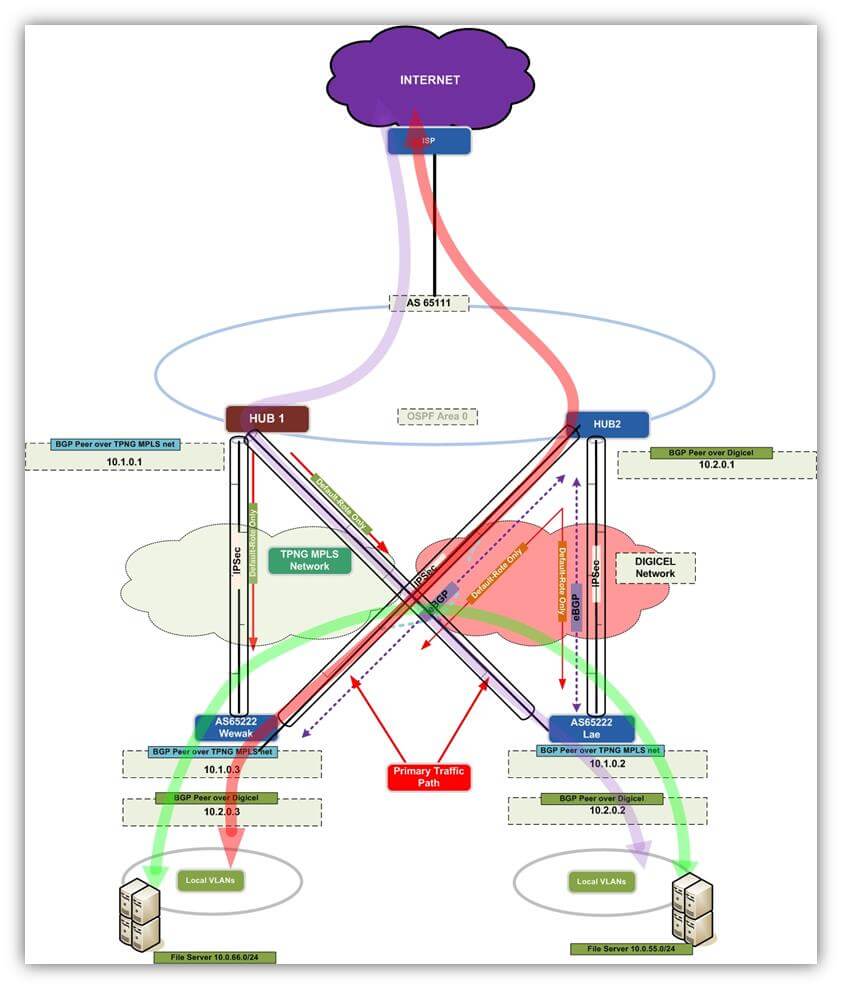
Figure 1: Secure Tunnelling solution with Automatic Failover.
Secure Your WAN Links
So how secure are your data links? Nowhere in the world, any Telco or service provider will vouch their data links are 100% secure, this is a known fact. This is no different in the Pacific Islands; in fact, the likelihood of this happening in the Pacific Islands is much greater. You’re bound to hear tales of fibre been uprooted, data centres and exchanges been vandalised. These threats are currently limited to the hardware and infrastructure build, but before long your intellectual property and data integrity will be at immense risk. So what can you do to safeguard data network right now – like today? The simplest solution is encrypting your data links. You don’t need to go buy any fancy firewall or build dedicated VPNs (although these are very valid options), but use enterprise-grade secure tunnelling. You can do this today if you have the right tools and people.
The article ‘How To Create A Stable and Secure Data Network’ is a blueprint for building secure data networks, use it. Don’t put it off.
Is Your Service Provider Delivering?
You buy a 2Mbps service between your branch office and HQ. If you’re the ICT manager two questions should immediately pop up.Question 1: What’s the guarantee you are indeed getting the throughput you paid for?Answer: You just have to take their word for it.Question 2: Can you trust your service provider?Answer: The straightforward answer is; you shouldn’t!We talked about elements beyond the control of service providers and we also touched on how some service providers take on more than they could chew, well this is how most service providers maximise their network’s utilisation. On your 2Mbps link, what throughput can you expect? Is there a benchmark on the acceptable throughput? And how could you verify this?The benchmark for throughput should be part of your SLA provided by your service provider. They should also supply the average Round-Trip Times. Use an enterprise-grade network performance monitoring tool to check your TCP throughput on a regular basis.If your network is not equipped with a TCP throughput monitoring tool, use the following technique to get a rough estimate. We use the method and formula described in RFC 6349 (https://tools.ietf.org/html/rfc6349). By punching a few numbers into your desktop calculator and using the formula below you can come up with a value that is close to what your service provider has promised, give or take 10%.When using TCP to transfer data the two most important factors are the TCP window size and the round-trip latency. If you know the TCP window size and the round trip latency you can calculate the maximum possible throughput of a data transfer between two hosts, regardless of how much bandwidth you have (based on RFC 6349).
The Formula To Calculate TCP Throughput.

We will attempt to illustrate this using a real-life example from one of our customers in Papua New Guinea with their HQ in Port Moresby and a branch in Kavieng. Our customer uses two service providers (Telikom PNG and Digicel) with an automatic failover option.
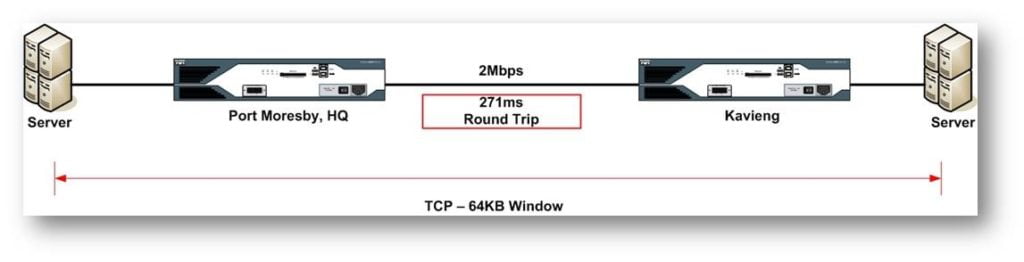
Figure 2: 2Mbps Link between Port Moresby, HQ and Kavieng over the Digicel Network.
The figure above depicts the point-to-point connectivity between the HQ and the branch over a 2Mbps link with a round-trip latency of 271 milliseconds (using the Digicel service). If we try to transfer a large file from a server in Port Moresby to a server in Kavieng using FTP, what is the best throughput we can expect? First, let’s convert the TCP window size from bytes to bits. In this case, we are using the standard 64KB TCP window size of a Windows machine.64KB = 65536 Bytes. 65536 X 8 = 524288 bitsNext, let’s take the TCP window in bits and divide it by the round trip latency of our link in seconds. So if our latency is 271 milliseconds we will use 0.271 in our calculation.524288 bits / 0.271 seconds = 1934642 bits per second throughput = 1.93Mbps maximum possible throughputAs a customer, you might view this as straight point-to-point connection, but from a service provider perspective, this connection could be multiple hops away, thus adding to the latency.A quick “Approximation” of the round trip delay: you could use a standard Windows machine to perform a basic PING test to another Windows machine over 2Mbps service. The screenshots below illustrate the output we performed over Digicel and Telikom PNG between Kavieng and Port Moresby.
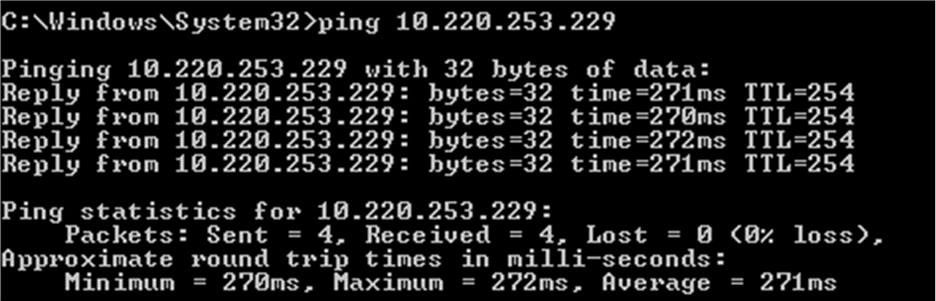
Figure 2: 2Mbps Link between Port Moresby, HQ and Kavieng over the Digicel Network.
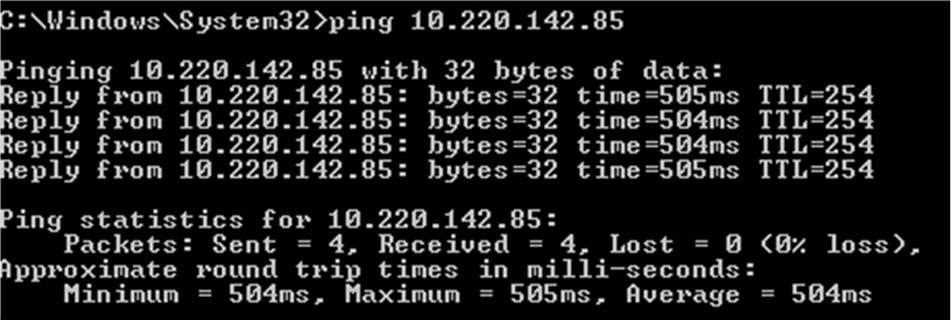
Figure 3: PING test over Telikom PNG
How Solid Is Your Core LAN/WAN Design
We were brought in by Superannuation Company to assist with a slow response problem. Our first reaction was it’s due to an ISP link issue. Then we verified the throughput, which was within SLA. Then we narrowed it down to the core infrastructure. The more we troubleshoot the problem the more we realised how poorly the core network was designed. Long story short…, the problem was due inconsistencies in the Spanning Tree protocol. The customer had a consumer grade 8 port hub/switch performing server aggregation coupled with Cisco switches and routers. Straight off the bat, this is a sign of bad network design. Worst of all there was no network diagram(s) to represent the network, creating more work and delaying the resolution.So the moral of the story is you cannot always control the service providers, but you can take better care of your own Network. To do that you need best practice design solutions that will scale well and accommodate growth.You cannot combat your companies own inertia if you keep treating your IT as just a cost centre. For IT to contribute towards organisations’ overall vision and deliver tangible value to the business it needs legs of its own. It needs people with the right technical know-how. It can do without the CFO who has the power to veto the ICT manager’s sound recommendation for 3 consecutive years to upgrade the WAN hardware (because WAN routers are only 8 years old) or improve redundancy by having a secondary ISP. Then turns around and blames IT for poor network performances. When do you “know” that your IT is falling short? You know when your marketing team comes up with the project/application to drive more business, but unable leverage the current IT capabilities. You know when you have excessive slow response times during files access locally or across the WAN.Even if I write a 3-page blog post on this topic, I doubt it would hardly scratch the surface. This is not a one-size fit all topic, nor there an ideal design that will be perfect 12 months from now. But, you could engineer your network using best practice network design to handle growth, minimise security risks and ease troubleshooting during a network outage together with clear concise Network diagrams.For aspiring ICT managers who are brave enough to take on the responsibility of redesigning your data networks use the following as a guide: Campus Wired LAN Technology Design Guide
Let's Get Started, Shall We?
Should you have any queries please do not hesitate to contact us, we’re just a click away! If you like to get on board, know more or to ask a question please drop us an e-mail: info@sprintnetworks.com